날짜 시각 데이터와 lubridate 패키지
작성일자:12/3~
작성자: 오소민,윤서현,조현우,최민슬,최준헌
POSIX
POSIX는 "Portable Operating System Interface of Unix"의 약자로, UNIX 시스템과 호환성을 제공하고 다양한 운영 체제 간의 이식성을 증가시키기 위한 표준을 정의하는 개별 규격 집합을 의미한다.
POSIX 표준은 IEEE(Institute of Electrical and Electronics Engineers)에서 개발하며, 다양한 운영 체제 환경에서 이식성 있는 소프트웨어를 개발하기 위한 규칙을 제공한다. 주로 UNIX 계열 운영 체제에서 사용되지만, 다른 운영 체제에서도 일부 POSIX 호환성을 가질 수 있다.
<POSIX의 기능>
1. 시스템 호출(System Calls) : 파일 조작, 프로세스 관리, 통신 등과 같은 기본적인 운영 체제 서비스에 대한 시스템 호출을 정의한다.
2. 라이브러리 함수(Library Functions) : 표준 C 라이브러리 함수와 함께 제공되는 추가적인 함수들을 포함한다.
3. 커맨드 인터페이스(Command-line Interface) : 명령줄 도구 및 명령어의 인터페이스를 표준화한다.
4. 프로세스 환경(Process Environment) : 프로세스 생성, 제어, 통신 및 동기화와 관련된 규칙을 정의한다.
5. 파일 및 디렉터리 구조(File and Directory Structure) : 파일 및 디렉터리 조작에 대한 표준을 제공한다.
POSIX time
POSIX time 이란, 1970년 1월 1일 00:00:00 UTC 로부터 현재까지의 누적된 초(seconds) 값을 의미한다.
(기준 시간이 1970년 1월 1일 00시 00분 00초 UTC 인 이유는, UNIX 운영체제의 최초 출시년도가 1971년이어서 그렇다.)
POSIX time 을 epoch time 또는 UNIX time 이라고도 부르는데,
이는 epoch 라는 단어가 특정 시대를 구분짓는 기준점(reference point from which time is measured = reference epoch) 이라는 의미를 가졌기 때문이다.
POSIX time 은 UNIX 운영체제를 개발한 벨 연구소에서 정의한 개념이다.
Date/Timestamp 데이터형을 Numeric 데이터형으로 표현 시, 기존에 Date/Timestamp가 갖는 한계점을 해결할 수 있어 UNIX time 의 개념이 도입되었다.
<Date/Timestamp 의 한계점>
1. 로컬 시간대(ex. KST) 명시 필요
2. 비연속적, 비선형적인 값이므로 계산 시 변환 필요
가령, ‘2021-05-23 09:00:00 KST’ 시간을 POSIX time으로 표현한다면
① KST(local time)를 UTC 로 변환해서, ‘2021-05-23 00:00:00 UTC’
② UNIX time 의 기준 시간인 ‘1970-01-01 00:00:00 UTC’ 에서부터 누적 초를 계산한다.
아래 숫자 값을 도출하게 된다.
‘1621728000’
협정세계시(UTC)
- 협정세계시(Coordinated Universal Time)란 국제적으로 표준화된 시간 표현 시스템으로 원자 시계를 기반으로 한다.
매우 정확한 시계로 1972년 이후 그리니치 표준시를 대체하여 국제 표준으로 사용되고 있다. 지구의 자전과 회전에 따른 시차를 보정하여 고정된 시간을 제공하며 세계 각 지역에서 시간을 일관되게 정의하여 다른 시간대나 다른 지역의 시간 차를 계산하기 쉽다. 현재 그레고리안 연도를 기준으로 하여 위도 0도, 본초 자오선에 위치한다.
UTC 계산
- 그레고리안 UTC는 시작점으로 사용되며 시스템 시간을 계산하기 위해 시스템의 UTC로부터 위치에따라 오프셋(UTC와 표준시간대의 차이)이 UTC에 추가된다. 오프셋은 시스템이 UTC의 서쪽 또는 동쪽인 시간 및 분 수를 지정한다. 서쪽은 -, 동쪽은 + 오프셋을 갖는다. 그 후 시스템 시간 계산을 위해 오프셋이 적용되면 시스템 시간은 하루 중 시간 시스템 값에 표시된다.
시차가 없는 기본 시간대로 시차가 필요한 경우 시간대 오프셋을 사용하여 현지 시간을 나타낼 수 있다.
예를 들어 한국 표준시는 UTC+9 즉 UTC로부터 9시간 뒤의 시간을 의미한다.
UTC는 국제적인 통신, 항공, 철도, 과학 연구 등에서 활용되며 세계 각국의 시간을 표준화하는데 중요한 역할을 하고 있다.
그리니치 평균시(GMT)
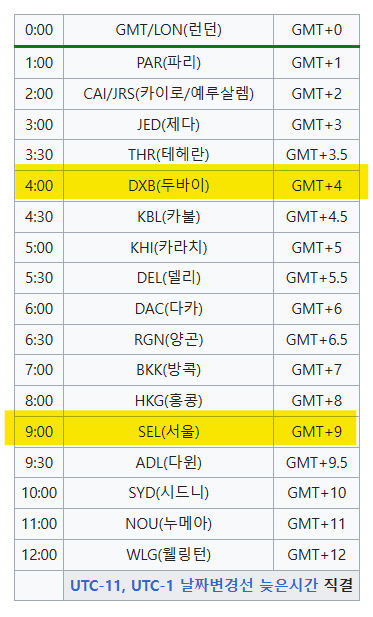
그리니치 평균시(GMT)는 Greenwich Mean Time의 약자이다. 영국 런던 그리니치 천문대를 기점으로 하는 협정 세계시(UTC)이다. 1972년 1월 1일 부터 협정 세계시(UTC)를 공식 표현으로 쓰고 있지만, UTC와 GMT를 일상에서 혼용되어 쓰기도 한다. 한국은 영국보다 9시간 빠르기 때문에 GMT +9:00라고 표시된다.영국이 시작점이기에 영국은 GMT+0으로 표현되고 두바이는 영국보다 4시간 빠르기 때문에 GMT+4로 표현된다. 영국보다 더 느린 나라는 -를 붙여서 표현한다.

<GMT 시간대>
네이버에 GMT 시간을 검색하여 그리니치 표준시(GMT)와 한국 표준시(KST)를 살펴보자. 실제 9시간 차이가 나는 것을 알 수 있다.
날짜 및 시간 형식 공부 내용
| 형식 지정자 | 형식 | 예 |
| %m/%d/%Y | mm/dd/yyyy | 02/21/2018 |
| %m/%d/%y | mm/dd/yy | 02/21/18 |
| %d/%m/%Y | dd/mm/yyyy | 21/02/2018 |
| %d/%m/%y | dd/mm/yy | 21/02/18 |
| %d-%m-%Y | dd-mm-yyyy | 21-02-2018 |
| %d-%m-%y | dd-mm-yy | 21-02-18 |
| %m-%d-%Y | mm-dd-yyyy | 02-21-2018 |
| %m-%d-%y | mm-dd-yy | 02-21-18 |
| %Y-%m-%d | yyyy-mm-dd | 2018-02-21 |
| %f/%e/%Y | m/d/yyyy | 2/21/2018 |
| %f/%e/%y | m/d/yy | 2/21/18 |
| %e/%f/%Y | d/m/yyyy | 21/2/2018 |
| %e/%f/%y | d/m/yy | 21/2/18 |
| %f-%e-%Y | m-d-yyyy | 2-21-2018 |
| %f-%e-%y | m-d-yy | 2-21-18 |
| %e-%f-%Y | d-m-yyyy | 21-2-2018 |
| %e-%f-%y | d-m-yy | 21-2-18 |
| %b %e, %Y | Mth d, yyyy | Feb 21, 2018 |
| %B %e, %Y | Month d, yyyy | February 21, 2018 |
| %b %d, %Y | Mth d, yyyy | Feb 21, 2018 |
| %B %d, %Y | Month d, yyyy | February 21, 2018 |
| %Y-%m-%d %H:%M:%S | yyyy-mm-dd hh:mm:ss | 2018-02-21 12:00:00 |
| %H:%M:%S | hh:mm:ss | 12:00:00 |
| %Y-%m-%d %I:%M:%S %p | yyyy-mm-dd HH:MM:SS tt | 2018-10-29 10:02:48 AM |
| %Y-%m-%d %I:%M:%S %p | yyyy-mm-dd HH:MM:SS tt | 2018-10-29 07:30:20 PM |
- %d: 일을 두 자리 숫자로 표시합니다. 01부터 31까지.
- %e: 일을 한 자리 숫자로 표시합니다. 1부터 31까지. 일이 한 자리 수인 경우 앞에 0을 붙이지 않습니다.
- %m: 월을 두 자리 숫자로 표시합니다. 01 (1월)부터 12 (12월)까지.
- %f: 월을 한 자리 숫자로 표시합니다. 1 (1월)부터 12 (12월)까지. 월이 한 자리 수인 경우 앞에 0을 붙이지 않습니다.
- %Y: 네 자리 연도를 표시합니다.
- %b: 월의 세 글자 약어를 표시합니다. Jan, Feb, Mar 등.
- %B: 월의 전체 이름을 표시합니다. January, February, March 등.
- %H: 24시간 형식의 시간을 두 자리 숫자로 표시합니다. 00부터 23까지.
- %I: 12시간 형식의 시간을 두 자리 숫자로 표시합니다. 01부터 12까지.
- %M: 분을 두 자리 숫자로 표시합니다. 00부터 59까지.
- %S: 초를 두 자리 숫자로 표시합니다. 00부터 59까지.
- %p: AM 또는 PM을 표시합니다. 12시간 형식( %I )에서 사용됩니다.
각 형식 지정자가 의미하는 바를 간단히 정리한 것이다. 사용자 정의 날짜 및 시간 형식을 생성할 때, %d, %m, %Y, %H, %M, %S 등과 같은 일련의 값들과 /, 쉼표, 공백과 같은 구분자들로 이루어진 형식 지정자들을 사용하여 일, 월, 년, 시, 분, 초를 지정할 수 있다. 이러한 형식 지정자들은 필요에 따라 서로 다른 구분자와 결합되어 다양한 형식의 날짜 및 시간 문자열을 생성할 수 있다.
사용자 정의 형식 지정자를 작성할 때, 날짜의 숫자 간 하나 이상의 구분자가 필요하다. %b %e, %Y는 Mth d, yyyy의 형식으로써 Feb 21, 2018 같은 날짜를 표현한다. 이때 21(일)과 2018(연도) 사이에는 쉼표,공백이라는 구분자가 존재하는 것이다.
> mybirthday_date <- as.Date("2004-03-12")
> formatted_mybirthday_date <- format(mybirthday_date, "%B %e, %Y")
> print(formatted_mybirthday_date)
[1] "3월 12, 2004"
하지만 %b%e%Y라는 지정자는 Feb212018이라는 날짜를 나타내는데 이는 날짜 숫자간에 아무런 구분자도 존재하지 않기 때문에 유효하지 않은 것이다.
> mybirthday_date <- as.Date("2004-03-12")
> formatted_mybirthday_date <- format(mybirthday_date, "%B%e%Y")
> print(formatted_mybirthday_date)
[1] "3월122004"유효하지 않다고 했는데 왜 오류가 안나는 건지 모르겠다... 유효하지 않을 뿐 코드는 돌아가는 건가..?
그러나 /,쉼표,공백 없이도 유효한 지정자를 만들 수 있는데 이는 월 이름 또는 월 이름을 세 자로 줄인 약어를 구분자로 사용하는 것이다. 예시로 %e%b%Y같은 경우는 21Feb2018의 형식으로 날짜를 표현한다.
> mybirthday_date <- as.Date("2004-03-12")
> formatted_mybirthday_date <- format(mybirthday_date, "%e%B%Y")
> print(formatted_mybirthday_date)
[1] "123월2004"march가 한국식인 3월로 표시되다 보니 12(일)과 3 사이에 아무런 구분자가 없다....?
조건부 형식 지정자
%e와 %d 모두 한 자리 또는 두 자리의 일로 사용될 수 있는 것은 동일하지만, %e는 한 자리 일을 한 자리 숫자로 표시하고, %d는 한 자리 일을 앞에 영(0)이 붙은 형태로 표시한다.
%f과 %m 또한 한자리 또는 두 자리 월로 사용될 수 있지만 %f는 한 자리 월을 한 자리 숫자로 표시하고, %m은 한 자리 월을 앞에 영(0)이 붙은 형태로 표시한다는 점에서 차이가 있다..
Sys.Date()
- 현재 시스템의 기본 시스템 시간대에서 현재 날짜를 " YYYY-MM-DD" 형식으로 반환하는 함수이다. 이때 시간은 포함하지 않으며 함수 이용시 대소문자에 유의하자!

이런식으로 현재 날짜를 YYYY-MM-DD 형식으로 알려줌을 볼 수 있다.
신기하게도 Sys.Date()는 일단위 +,- 계산이 가능하다.
다음을 살펴보자.

이렇게 계산이 되는걸 볼 수 있다.
+ 또한 원하는 포맷대로 표시하고 싶을 때는 format()을 사용할 수 있다.
%Y - 4자리 년도
%y - 2자리 년도
%m - 2자리 월
%d - 2자리 일
%a - 한 글자 요일
%A - 세 글자 요일
그리고 시간이 포함되지 않는다하였지만 다음을 사용하면 표시할 수 있다.
%H - 시
%M - 분
%S - 초
사용하는 예시는 다음과 같다.

이렇게 활용 가능하다.
이러한 방식으로 Sys.Date()함수를 통해 현재 날짜를 반환해 낼 수 있다.
Sys.time()
Sys.time()은 현재 날짜-시간 값을 초단위까지 반환한다. Sys.time은 POSIXct 클래스 객체를 반환한다.
일단 간단히 예제를 봐보자.
현재 시간은 UTC 기준 2023-12-03 18:28:58 KST이다.
# 현재 시간을 얻어와 POSIXct 객체로 저장하기
current_time <- Sys.time()
current_time
[1] "2023-12-03 18:28:58 KST"
다음 current_time을 format해서 "2023년 12월 03일 18시 28분 58초"로 형식을 변경하고 싶다고 하자. 앞에서 배운 날짜 시간 포맷팅 형식을 이용해서 코드를 작성해보았다.
formatted_date <- format(current_time, format="%Y년 %m월 %d일 %H시 %M분 %S초 %Z")
formatted_date[1] "2023년 12월 03일 18시 28분 58초 KST"
format()
R의 format() 함수는 벡터의 데이터를 사람이 읽을 수 있는 문자열로 형식화하는 데 사용된다. 특히 날짜와 시간 객체를 다룰 때 이 함수는 매우 유용하다. 앞서 배운 다양한 형식 지정자를 사용하여 날짜, 시간, 숫자 등을 원하는 형식의 문자열로 변환할 수 있다.
> # 현재 시스템 시간을 가져옴
> current_time <- Sys.time()
>
> # 기본 형식
> print(format(current_time))
[1] "2023-12-04 00:33:01"
>
> # 사용자 지정 형식
> formatted_time <- format(current_time, "%Y-%m-%d %H:%M:%S")
> print(formatted_time)
[1] "2023-12-04 00:33:01"
공공데이터에서 ' 인천국제공항공사_화물기 동계 정기운항편 출발' 데이터 파일을 이용해보았다.


library(readr)
data <- read_csv("GitHub/(인천공항)2018년_화물기.csv",
locale = locale(encoding = "CP949"))
# '시작일자' 열을 Date 객체로 변환
data$시작일자 <- as.Date(data$시작일자, format = "%Y-%m-%d")
# '종료일자' 열을 Date 객체로 변환
data$종료일자 <- as.Date(data$종료일자, format = "%Y-%m-%d")
data$시작일자와 data$종료일자를 사용하여 날짜 데이터를 Date 객체로 변환하는 것이다. 이 코드는 각 날짜 문자열을 '연도-월-일' 형식에 맞게 변환한다. R에서 열 이름에 한글이 포함된 경우, 열 이름을 따옴표 없이 바로 사용할 수 있다.
만약 '시작일자'와 '종료일자' 열이 다른 형식으로 날짜를 포함하고 있다면, format 매개변수를 날짜 형식에 맞게 조정해야 한다. 데이터 프레임의 열 이름을 코드에 정확히 맞추어야 하며, 열 이름이나 파일 경로에 특수문자나 공백이 있는 경우 적절한 처리가 필요할 수 있다.
아시아나 항공의 월요일 시작일자와 종료일자를 추출해보겠다.
먼저 해당 데이터가 있는 행들을 필터링하고, 필요한 열만 선택하는 작업을 해야 합니다. R에서 이러한 데이터 조작은 dplyr 패키지를 사용하여 쉽게 수행할 수 있다.
다음은 dplyr 패키지를 사용하여 아시아나 항공의 월요일 시작일자와 종료일자를 추출하는 코드이다:
> # data 는 이미 불러온 데이터 프레임 변수입니다.
>
> # 아시아나 항공의 월요일 데이터를 필터링하고 시작일자와 종료일자를 선택합니다.
> asiana_monday_dates <- data %>%
+ filter(항공사 == "아시아나항공", 운항요일 == "월요일") %>%
+ select(시작일자, 종료일자)
>
> # 결과 출력
> print(asiana_monday_dates)
# A tibble: 34 × 2
시작일자 종료일자
<date> <date>
1 2018-10-29 2019-03-30
2 2018-11-19 2018-11-19
3 2018-11-26 2018-11-26
4 2019-02-09 2019-03-30
5 2018-11-19 2018-11-19
6 2018-11-26 2018-11-26
7 2018-10-28 2019-02-07
8 2019-01-01 2019-03-29
9 2018-10-29 2018-12-30
10 2019-01-05 2019-01-08
# ℹ 24 more rows
# ℹ Use `print(n = ...)` to see more rows
filter() 함수를 사용하여 '항공사'가 "아시아나항공"이고, '운항요일'이 "월요일"인 행만 선택한다.
select() 함수를 사용하여 '시작일자'와 '종료일자' 열만을 선택한다.
날짜를 '년도-월-일' 형식에서 '월 일, 년도' 형식으로 변경한다: %Y-%m-%d ------> %B %d, %Y
> library(dplyr)
>
> # 아시아나 항공 월요일의 시작일자와 종료일자를 포맷팅하기 위한 코드
> asiana_monday_formatted_dates <- data %>%
+ filter(항공사 == "아시아나항공", 운항요일 == "월요일") %>%
+ mutate(
+ 시작일자_포맷팅 = format(as.Date(시작일자, format = "%Y-%m-%d"), "%B %d, %Y"),
+ 종료일자_포맷팅 = format(as.Date(종료일자, format = "%Y-%m-%d"), "%B %d, %Y")
+ ) %>%
+ select(시작일자_포맷팅, 종료일자_포맷팅)
>
> # 결과 출력
> print(asiana_monday_formatted_dates)
# A tibble: 34 × 2
시작일자_포맷팅 종료일자_포맷팅
<chr> <chr>
1 10월 29, 2018 3월 30, 2019
2 11월 19, 2018 11월 19, 2018
3 11월 26, 2018 11월 26, 2018
4 2월 09, 2019 3월 30, 2019
5 11월 19, 2018 11월 19, 2018
6 11월 26, 2018 11월 26, 2018
7 10월 28, 2018 2월 07, 2019
8 1월 01, 2019 3월 29, 2019
9 10월 29, 2018 12월 30, 2018
10 1월 05, 2019 1월 08, 2019
# ℹ 24 more rows
# ℹ Use `print(n = ...)` to see more rows
mutate() 함수를 사용하여 '시작일자'와 '종료일자' 열에 대해 as.Date()로 날짜 타입으로 변환한 후, format() 함수로 날짜 형식을 변경하고 있다. 이후 select() 함수로 포맷팅된 날짜 열만을 선택하여 출력한다.
as.Date()
: R에서는 기본적으로 as.Date() 함수를 써서 일반 텍스트 데이터를 날짜 데이터로 바꾼다.
as.Date('2023-12-06')
->예를 들어서, 오늘 날짜는 이렇게 표현할 수 있다.
<에러가 뜨는 경우>
#따옴표 없이 쓴 경우(as.Date()는 '텍스트 데이터'를 날짜 데이터로 바꾼다)
as.Date(2023-12-06)
#빼기(-) 부호 없이 숫자로만 쓴 경우
as.Date(20231206)
#따옴표를 써서 문자 데이터로 표시할 때도 미리 약속한 패턴과 다르면 역시 에러가 나온다.
as.Date('20231206')
>>반면 lubridate에 들어 있는 ymd() 함수는 어떤 모양이든 이를 날짜로 받아들인다.( year, month, day )
ymd('20231206')
ymd("2011/06/04")
## [1] "2011-06-04"
#미국식 날짜로 표기한 것
mdy("06/04/2011")
## [1] "2011-06-04"
Dates + Times
“2023년 12월 4일” 에 구체적인 시각까지 더해서, “2023년 12월 4일 13시 30분 50초” 를 R에서 만들어 보겠다.
시각까지 더해진 정보는 Date class 로 정보를 담을 수 없다.
즉 as.Date() 함수로 2023년 12월 4일 13시 30분 50초 정보를 만들 수 없다.
as.Date("2023-12-04 13:30:50") # 시각정보가 사라짐
## [1] "2023-12-04"
->포직스(POSIX) 를 이용하면 나타낼 수 있다.
as.POSIXct("2023-12-04 13:30:50")
## [1] "2023-12-04 13:30:50 KST"
temp <- as.POSIXlt("2023-12-04 13:30:50") # list 기반
이번엔 lubridate package 의 경우이다.
lubridate package 에는 “y”, “m”, “d” 뿐만 아니라 “h”, “m”, “s” 도 있다.
(hour, minute, second)
“y”, “m”, “d” 와 “h”, “m”, “s” 를 잘 조합하여 사용하면 비교적 편하게 “2011년 6월 4일 13시 30분 50초” 정보를 담을 수 있다.
ymd_hms("2023-12-04 13:30:50")
## [1] "2023-12-04 13:30:50 UTC"
strptime()
strptime() 함수는 문자열을 날짜 및 시간 형식으로 변환하는 함수이다. 주어진 문자열을 특정한 형식으로 해석하여 'POSIXlt' 또는 'POSIXct' 객체로 변환한다.
* POSIXlt(List-based Time)
-> 리스트 기반의 구조로, 여러 가지 구성 요소로 날짜 및 시간을 표현한다.
-> 구성 요소에는 연, 월, 일, 시, 분, 초, 요일, 일년 중 몇번째 날인지 등이 포함된다.
-> 인덱싱을 통해 각 구성 요소에 접근이 가능하다.
-> 시간대 변환에 유용하며, 여러 가지 날짜 및 시간 연산을 지원한다.
lt_time <- as.POSIXlt("2023-12-06 10:30:00")
lt_time$hour
[1] 10
* POSIXct(Calendar Time)
-> 단일 숫자(타임스탬프)로 날짜 및 시간을 표현한다.
-> 타임스탬프는 1970년 1월 1일 00:00:00 (UTC)로부터 경과한 초 단위의 시간이다.
-> 계산이나 시간 간격을 다룰 때 효과적이며, 숫자형으로 저장되기 때문에 계산이 더 빠르다.
-> POSIXlt보다 메모리 사용이 적지만, 특정 상황에서는 정확한 형태의 날짜 및 시간 정보를 얻기 어려울 수 있다.
ct_time <- as.POSIXct("2023-12-06 10:30:00")
format(ct_time, "%Y-%m-%d %H:%M:%S")
[1] "2023-12-06 10:30:00"
아래의 코드를 실행하여 POSIXct의 저장 형태를 알아본 결과, 실제로 1970년 1월 1일 00:00:00로부터 경과한 초 단위의 시간이 저장되는 것을 확인할 수 있다.
datetime <- as.POSIXct("2023-12-06 10:30:00")
timestamp <- as.numeric(datetime)
print(timestamp)
[1] 1701858600
*** 일반적으로, 시간대를 고려하지 않는 간단한 작업에는 'POSIXct'를 사용하는 것이 더 간편하고 효율적이지만, 시간대 정보나 구체적인 날짜 관련 연산이 필요한 경우에는 'POSIXlt'를 사용하는 것이 효과적이다.
<strptime()의 기본 형식>
str <- "2023-12-06 10:30:00"
format <- "%Y-%m-%d %H:%M:%S"
parsed_time <- strptime(str, format)str : 변환하려는 문자열
format : 해당 문자열의 날짜 및 시간 형식을 지정하는 문자열
* format의 기본 형식 : %Y-%m-%d %H:%M:%S
%Y : 4자리 연도
%m : 월(01부터 12까지)
%d : 일(01부터 31까지)
%H : 24시간 형식의 시간(00부터 23까지)
%M : 분(00부터 59까지)
%S : 초(00부터 59까지)
-> strptime() 함수는 'POSIXlt' 객체를 반환하며, 이 객체는 날짜 및 시간 정보를 구조화된 형태로 포함한다. 만약, 'POSIXct' 객체를 얻고 싶다면, 'as.POSIXct()' 함수를 사용하면 된다.
parsed_time_ct <- as.POSIXct(parsed_time)
* strptime() 함수는 문자열을 날짜 및 시간 형식으로 파싱할 때 지정된 형식에 따라 정확한 문자열이어야 한다. 만약, 형식이 맞지 않을 경우에는 NA(결측치)가 반환된다.
<strptime()의 사용 예시>
str <- "2023-12-06 10:30:00"
format <- "%Y-%m-%d %H:%M:%S"
parsed_time <- strptime(str, format)
print(parsed_time)
[1] "2023-12-06 10:30:00 UTC"위의 코드를 실행하면 이와 같이 문자열이 날짜 및 시간 형식으로 변환된 결과가 나온다.
strftime()
strftime() 함수는 날짜 및 시간 객체를 형식화된 문자열로 반환화는 함수이다. 즉, strptime()과 반대 기능을 수행하는 함수이다.
* strptime() : 문자열 -> 날짜 및 시간 형식
* strftime() : 날짜 및 시간 -> 형식화된 문자열
<strftime()의 기본 형식>
strftime(x, format = "")x : 형식화하려는 날짜 및 시간 객체 ('POSIXlt' 또는 'POSIXct')
format : 반환할 문자열의 형식을 지정하는 문자열. 생략될 경우, 기본 형식을 사용.
<strftime()의 사용 예시>
ct_time <- as.POSIXct("2023-12-06 10:30:00")
formatted_str <- strftime(ct_time, format = "%Y-%m-%d %H:%M:%S")
print(formatted_str)
[1] "2023-12-06 10:30:00"위와 같이 strftime()을 활용해 형식화된 문자열로 변환할 수 있다.
lubridate 패키지 공부한 내용 첨부
lubridate는 날짜&시각 데이터를 원활하게 가공하는데 도움을 줄 목적으로 만들어졌다. lubridate는 날짜 및 시간에 대한 기본 연산을 수행할 수 있어서 dplyr랑 stringr, tidyr 같은 패키지와 함께 쓰일수도 있다. 일단은 lubridate의 대표 함수들에 대해 알아보자.

■ PARSE DATE-TIMES
Parsing 이라는 단어가 생소 할수도 있다. Parsing(파싱)은 주어진 데이터를 의미있는 부분으로 나누고 해석하는 과정을 뜻한다. 날짜-시각 Parsing 대표 함수에는 ymd_* 계열 함수, ydm_* 계열 함수, mdy_* 계열 함수. dmy _*계열 함수, ymd(),ydm(),mdy(),dmy(),myd(),dym() 함수가 있다.
기본적으로 이 형식을 알아야한다. year(y),month(m),day(d),hour(h),minute(m),second(s) 순서로 시간과 날짜가 인식된다.
날짜 데이터가 다양한 형식으로 입력이 되는데
Ex) 2023-11-29 , 11/29/2023 , 29 November 2023
각각의 형태에 맞춰서 동일한 형식(ex) POSIXct)로 바꾸는 과정이 필요하다.
1) ymd _*계열 함수: ymd_hms(), ymd_hm(),ymd_h(),ymd()함수
ymd_* 의 입력값의 형태는 년:월:일 시간 관련 요소들이다.+ymd 자체는 년월일로
hms이면 시:분:초 다 포함하고 hm 이면 시:분만 h 이면 시 요소만 입력한다.
이 형식으로 입력하면 POSIXct 값((YYYY-MM-DD 시:분:초 UTC))으로 결과값을 반환한다.
library(lubridate)
# ymd
ymd_datetime <- ymd("20231129")
ymd_datetime
# ymd_hms
ymd_hms_datetime <- ymd_hms("2023-11-29 12:18:45")
ymd_hms_datetime
# ymd_hm
ymd_hm_datetime <- ymd_hm("2023-12-01 13")
ymd_hm_datetime
# ymd_h
ymd_h_datetime <- ymd_h("2023.11.29.12")
ymd_h_datetime[1] "2023-11-29"
[1] "2023-11-29 12:18:45 UTC"
[1] "2023-01-02 01:13:00 UTC"
[1] "2023-11-29 12:00:00 UTC"어떤 모양으로 입력해도 구분만 잘되어 있으면 인식 할수 있다.
2) ydm_* 계열 함수: ydm_hms(),ydm_hm(),ydm_h(),ydm()함수
ydm_* 의 입력값의 형태는 년:일:월 시간 관련 요소들이다.+ydm 자체는 년일월로
hms이면 시:분:초 다 포함하고 hm 이면 시:분만 h 이면 시 요소만 입력한다.
이 형식으로 입력하면 POSIXct 값(YYYY-MM-DD 시:분:초 UTC)으로 결과값을 반환한다.
# Using ydm
ydm_datetime <- ydm("2023-30-11")
ydm_datetime
# Using ydm_hms
ydm_hms_datetime <- ydm_hms("20233011 12:34:40" )
ydm_hms_datetime
# Using ydm_hm
ydm_hm_datetime <- ydm_hm("202330111234" )
ydm_hm_datetime
# Using ydm_h
ydm_h_datetime <- ydm_h("2023.30.11.12")
ydm_h_datetime[1] "2023-11-30"
[1] "2023-11-30 12:34:40 UTC"
[1] "2023-11-30 12:34:00 UTC"
[1] "2023-11-30 12:00:00 UTC"
3) mdy_* 계열 함수: mdy_hms(),mdy_hm(),mdy_h(),mdy()
mdy_* 의 입력값의 형태는 월:일:년 시간 관련 요소들이다. +mdy 자체는 월일년으로 출력한다.
# Using mdy
mdy_datetime <- mdy("11/30/2023")
mdy_datetime
# Using mdy_hms
mdy_hms_datetime <- mdy_hms("11/30/2023 12:25:13")
mdy_hms_datetime
# Using mdy_hm
mdy_hm_datetime <- mdy_hm("113020231225")
mdy_hm_datetime
# Using mdy_h
mdy_h_datetime <- mdy_h("11.30.2023.12")
mdy_h_datetime[1] "2023-11-30"
[1] "2023-11-30 12:25:13 UTC"
[1] "2023-11-30 12:25:00 UTC"
[1] "2023-11-30 12:00:00 UTC"
4)dmy_*계열 함수: dmy_hms(),dmy_hm(),dmy_h(),dmy()
dmy_* 의 입력값의 형태는 일:월:년 시간 관련 요소들이다. +dmy ()는 일,월,년 형태로 출력한다.
# Using dmy
dmy_datetime <- dmy("30/11/2023")
dmy_datetime
# Using dmy_hms
dmy_hms_datetime <- dmy_hms("30 November 2023 12:29:30")
dmy_hms_datetime
# Using dmy_hm
dmy_hm_datetime <- dmy_hm("2th November 2023 12 29")
dmy_hm_datetime
# Using dmy_h
dmy_h_datetime <- dmy_h(3011202312)
dmy_h_datetime[1] "2023-11-30"
[1] "2023-11-30 12:29:30 UTC"
[1] "2023-11-02 12:29:00 UTC"
[1] "2023-11-30 12:00:00 UTC"
여기서 주목해야할 점은 2th November 2023으로 써도 날짜 형식으로 인식한다는 것이다. 또한, 따옴표를 쓰지 않고 숫자를 여러개 늘여도 다 알아들어 POSIXct 형식으로 바꿔준다.
이외로 myd() 함수 ,dym() 함수도 있다.
■GET AND SET COMPONETS
이 함수들은 날짜&시각 데이터들을 분해하여 추출하는 역할을 한다.
<주요기능>
date() :날짜 부분을 반환한다.
year() : 연도 부분을 추출한다.
month():월 부분을 추출한다.
day():월의 일자를 [ex) 11월 13일이면 13일을 추출] 한다
#현재 시간 생성
library(lubridate)
current_date <- Sys.Date()
current_date
# 년, 월 빼기기
date_components<-c(year(current_date),month(current_date),day(current_date))
date_components
[1] 2023 12 3
공공데이터 파일들을 보면 날짜와 관련 열이 있는데 이 함수들을 이용하면 손쉽게 날짜 정보를 분리할 수 있을 거 같다.
wday():날짜-시간 객체에서 요일을 숫자로 반환한다. label이 T이면 요일이름을 반환하고 False이면 숫자로 반환한다. week_start 매개변수는 lubridate week 옵션을 따른다.
wday(x, label = FALSE, abbr = TRUE, week_start = getOption("lubridate.week.start", 7), locale = Sys.getlocale("LC_TIME") )#wday() 관련 예제
x <- as.Date("2009-09-02")
wday(x) # 4
wday(x, label = TRUE) # Wed
wday(x, week_start = 1) # 3
wday(x, week_start = 7) #4
[1] 4
[1] 수
Levels: 일 < 월 < 화 < 수 < 목 < 금 < 토
[1] 3
[1] 4
기본적으로 주의 흐름은 이렇다.
<1주를 카운팅한 기본적 흐름>
월 : 1 화: 2 수: 3 목: 4 금:5 토:6 일:7 이라고 하자.
우리는 week_start를 변경을 하여 시작점을 달리 할 수 있다.
wday(x,week_start=1) 일때 , week_start는 월요일을 시작점으로 설정했다는 말이다. 따라서 우리가 알고 있는 대로 수요일은 3번째가 된다.
반면 week_start=7로 설정했을때 일요일을 시작점으로 하겠다는 거다. 그러면 일요일부터 주가 시작되고 수요일은 4가 된다.
qday():날짜-시간 객체에서 날짜의 분기를 추출한다.
# Load the lubridate library
library(lubridate)
# Create an example date: October 10, 2022
example_date <- ymd("2022-10-10")
# Use qday() function to extract the quarter
quarter_of_example <- qday(example_date)
quarter_of_example
hour(): 시간 부분을 추출한다.
minute(): 분 을 추출한다.
second():초를 추출한다.
다음은 전라남도_식당영업시간정보 csv 파일이다.
해당 영업시작열 데이터는 시간: 분: 초 형식으로 되어 있다.
일단 영업시간 열에서 시(hour)부분만 추출하여 8시에 여는 식당이 몇개이고 11시에 여는 식당은 몇개이고 그런지를 추출하고 barplot으로 나태내려고 한다.
<구성>
- 전라남도_식당영업시간정보 파일 가져오기
- 영업시작시간 열을 hms() 를 이용하여 POSIXct 객체로 변환하기
- 영업시작 열에서 hour 부분만 추출하여 따로 저장하기
- table 함수로 해당 숫자 갯수 세주기
- barplot으로 bar 그래프 그려주기
getwd()
library(dplyr)
library(readr)
# 전라남도_식당영업시간정보 파일 가져오기
data <- readr::read_csv("전라남도_식당영업시간정보_20201125.csv")
data <- data %>% tidyr::drop_na()
# hms 이용해서 POSIXct 객체로 변환하기
hms_data <- hms(data$영업시작시간)
# 영업시작 열에서 hour 부분만 따로 추출해서 저장하기
extract_hour <- hour(hms_data)
extract_hour
# table 함수로 갯수 세어주기
before_barplot <- table(extract_hour)
before_barplot
# 그래프 그려주기
barplot(before_barplot,ylim=c(10,8000),xlab="영업시간",ylab="식당 갯수",main="전라남도_식당영업정보")

다음 그래프 결과로 11시에 영업을 시작하는가게가 제일 많은 것을 한눈에 알 수 있다. 이렇게 lubridate를 알고 있으면 날짜 데이터 분석에 유용함을 증명할 수 있다.
week(): 주를 날짜-시간 객체에서 추출한다.
quarter(): 날짜-시간 객체에서 분기를 추출한다. quarter은 1분기부터 4분기로 나뉜다.
lubridate 와 stringr 연관성
날짜& 시간 데이터가 문장 안에 들어 가있는 경우에 정규식을 이용하여 따로 추출해 올 수 있다.
week(), quarter() 함수와 stringr을 함께 이용한 예시를 설명하려고 한다.
인천광역시 남동구도서관 홈페이지자료현황 csv 파일에는 제목 열에 자료현황 수정일 데이터가 들어 있다.
어떤 형식으로 넣어져 있냐면 "자료현황수정일_20190821"로 되어 있다. stringr을 통해 날짜 부분만 추출하고 당시 그 날짜의 주(week)는 어떻게 되는지 알아보자. 또한, 날짜의 월(month)만 추출하여 quarter() 함수에 넣은후 각각 몇분기인지 분석해보자.
<구성>
1.파일불러오기 => 인천 도서관 csv
2.제목 열에서 자료현황 수정일과 날짜 stringr을 통해 분리하기=> str_match() 사용하기
3.week()로 당시 주가 어케 되는지 분석하기 + table() 함수로 갯수 세고 bar로 시각화하기
4.quarter()로 month(월)만 추출하여 분기 수 구해보고 bar로 시각화하기.
# 필요한 라이브러리 불러오기
library(dplyr)
library(stringr)
# Excel 파일 "인천 도서관.xlsx" 불러오기
library_data <- readxl::read_excel("인천 도서관.xlsx")
# "제목" 열에서 stringr을 사용하여 날짜 정보 추출
date <- library_data$제목 %>% stringr::str_match(pattern="\\d+")
date <- ymd(date)
date
# week() 함수를 사용하여 주 찾기 및 table() 함수로 갯수 세기, barplot으로 시각화
extract_week <- week(date)
count_week <- table(extract_week)
count_week
barplot(count_week, xlim=c(0,50), xlab="ISO 주 기준 week", ylab="수",width=3)
# quarter() 함수를 사용하여 월에서 분기 정보 추출하고 barplot으로 시각화
extract_month <- month(date)
how_quarter <- quarter(extract_month)
how_quarter
count_quarter <- table(how_quarter)
barplot(count_quarter, xlab="분기 항목(1~4)", ylab="갯수", main="자료수정 날짜 분기 관련 데이터")
* 날짜를 week () 하면 왜 다양한 주가 나온다. => 1년은 53주로 이루어져있기 때문에 다음과 같이 나온다.
=> 다음 년도로 바뀌면 다시 counting 되는 것이다.
[1] 34 34 34 34 3 3 35 3 53 39 40 1 5 5 5 5 18 18
[19] 18 18 18 10 10 10 10 10 13 13 13 13 13 21 21 43 43 43
[37] 43 43 43 6 7 7 7 6 15 15 15 15 15


semester():날짜-시간 객체에서 학기를 추출한다. 학기(semester)은 1년에 2 부분으로 나뉜다. 1학기 2학기 처럼 말이다.
x <- ymd(c("2023-03-26", "2022-07-23"))
semester(x)[1] 1 2
기타 함수
leap_year(): 해당 연도가 윤년인지 아닌지 확인한다.
update(): 날짜-시간 객체의 구성 요소를 수정한다.
am(): 날짜-시간 객체의 시간이 오전인지 여부를 논리값으로 반환한다.
pm(): 날짜-시간 객체의 시간이 오후인지 여부를 논리값(T,F)로 반환한다.]
■Round Date times
날짜 데이터도 기본적인 베이스는 숫자로 이루어져 있기 때문에 내림 ,올림 , 반올림을 할 수 있다.
floor_date()
floor_date() 함수는 단위별로 날짜-시간 객체를 내림 처리한다.

floor_date(
x,
unit = "seconds",
week_start = getOption("lubridate.week.start", 7)
)
#floor date 활용 예제
date <- ymd_hms("2023-12-25 12:01:59.23")
floor_date(date, ".1s")
floor_date(date, "second")
floor_date(date, "minute")
floor_date(date, "week")
floor_date(date, "quarter")[1] "2023-12-25 12:01:59 UTC"
[1] "2023-12-25 12:01:59 UTC"
[1] "2023-12-25 12:01:00 UTC"
[1] "2023-12-24 UTC"
[1] "2023-10-01 UTC"기본적인 원리는 다음과 같다. 일부만 설명하도록 하겠다.
[2]초(second)단위로 내림을 하면 뒤에 0.23s는 버려져서 59초만 남는다.
[3]분(minute)단위로 내림을 하면 59초(second)는 버려지고 분만 남는다.
단, 조금 신기한 단위가 있다. 바로 week와 quarter 단위이다.
week(주) 단위로 내림 처리를 하면 해당 날짜가 속한 주의 첫번째 날짜로 내림 처리가 된다. 달력을 보면 12/25 이 속한 주에 첫번째 날짜는 12/24이다. 따라서, 12/24가 내림 값으로 도출된다.
quarter()를 단위로 하면 해당 날짜가 속한 분기의 첫번째 날짜로 내림 처리 된다. 우리는 총 12달로 이루어져 있고 12월은 10/1일부터 시작되는 4분기에 속해 있다. 따라서, 10/1일이 내림 된 숫자가 된것이다.

round_date
round_date() 함수는 단위 별로 날짜-시간 객체를 반올림 처리한다.
round_date(
x,
unit = "second",
week_start = getOption("lubridate.week.start", 7)
)
date <- ymd_hms("2023-12-25 12:01:59.23")
round_date(date, "2 hours")
round_date(date, "day")
round_date(date, "month")
round_date(date, "halfyear")
[1] "2023-12-25 12:00:00 UTC"
[1] "2023-12-26 UTC"
[1] "2024-01-01 UTC"
[1] "2024-01-01 UTC"
[1] 2시간 간격을 단위로 하면, 2023-12-25 12:01:59.23은 12:00:00와 더 가까이 있기 때문에 내림된 결과인거다.
[2] 하루는 24시간인데 그 중간값인 12시를 넘은 12시 1분이므로 12/26일로 올림된다.
[3]1달은 30일 혹은 31일인데 12/25는 1월에 더 가깝기 때문에 1/1로 올림된다.
[4]이미 반년은 훌쩍 지났기 때문에 1/1로 올림된다.
ceiling_date
ceiling_date() 함수는 주어진 시간 단위의 경계로 날짜-시간을 올림 처리하는 함수이다.

ceiling_date(
x,
unit = "seconds",
change_on_boundary = NULL,
week_start = getOption("lubridate.week.start", 7)
)
date
ceiling_date(date, "second")
ceiling_date(date, "bimonth")
ceiling_date(date,"2 months")
ceiling_date(date, "bimonth") == ceiling_date(date, "2 months")
[1] "2023-12-25 12:02:00 UTC"
[1] "2024-01-01 UTC"
[1] "2024-01-01 UTC"
[1] TRUE[1]단위가 초(second)일때, 12시 2분으로 올림해주었다.
[4] ceiling_date 의 단위가 각각 bimonth와 2 months 일때 올림되는 날짜의 진위를 비교해보면 T로 도출된다.
■Stamp Date times
stamp()
stamp_date()
stamp_time()
stamp 함수들은 format()의 기능과 비슷하지만 조금 다른 차이점이 있다. 주어진 문자열에서 템플릿을 얻고, 그 템플릿을 기반으로 새로운 함수를 생성한다. 이 함수는 다른 날짜 및 시간 값을 주어진 템플릿에 맞게 서식화 할수 있다.
즉, "Created on Sunday, Jan 1" 라는 문자열이 있다고 하자. stamp() 로 다음 템플릿을 토대로 함수를 만든다. 다음 함수에 새로운 날짜 데이터 [(ex) 2024-04-05] 이 들어오면 포맷팅하여 "Created on Sunday 04 05" 라는 새로운 문자열이 형성된다.
stamp_date()와 stamp_time()은 날짜와 시간에 더 특화되어 있다.
<기본 형식>
stamp(
x,
orders = lubridate_formats,
locale = Sys.getlocale("LC_TIME"),
quiet = FALSE,
exact = FALSE
)
stamp_date(x, locale = Sys.getlocale("LC_TIME"), quiet = FALSE)
stamp_time(x, locale = Sys.getlocale("LC_TIME"), quiet = FALSE)
# 예제 문자열을 기반으로 날짜에 대한 템플릿 생성
date_template <- stamp_date("Date: 2022-12-01")
# 날짜 템플릿을 사용하여 날짜를 형식화
formatted_date <- date_template(ymd("2023-05-15"))
formatted_date
[1] "Date: 2023-05-15"
# 예제 문자열을 기반으로 시간에 대한 템플릿 생성
time_template <- stamp_time("Time: 15:04:00")
# 시간 템플릿을 사용하여 시간을 형식화
formatted_time <- time_template(hms("12:45:30"))
formatted_time
■Time Zones
with_tz()
다른시간대에서 같은 순간을 보고 싶은 경우가 있다.
with_tz는 각기 다른 시간대에서 나타날수 있는 시간과 날짜를 변환해준다.실제 시간은 변하지 않고 다른 지역에서 나타나는 시간대를 , 사용자가 설정한 시간대 위주로 바꿔주는 거다. 예를 들어 프랑스 파리 기준오후 5시일때 한국 시간을 알고 싶으면 with_tz()을 사용하여 변환 할 수 있다. with_tz() 함수에 인식되지 않은 시간대가 입력되면 협정세계시(UTC)로 기본 설정된다.
current_time <- Sys.time()
Japan_current_time <- with_tz(current_time,tz="Europe/Paris")
current_time;Japan_current_time[1] "2023-12-03 18:56:41 KST"
[1] "2023-12-03 10:56:41 CET"
force_tz()
시간대를 다른 것으로 설정하고 싶을 때가 있다.
force_tz()는 시간을 바꾸지 않고 강제로 시간대만 바꾸는 함수이다. tzone 인수에 datetime과 새 시간대를 전달하기만 하면 된다.
library(lubridate)
mar_11 <- ymd_hms("201731112:00:00")
mar_11
force_tz(mar_11,tzone="America/New_York")
[1] "2017-03-11 12:00:00 UTC"
[1] "2017-03-11 12:00:00 EST"시간을 바꾸지 않고 UTC 기준 시간대를 EST로 바꾸는 작업이다.
lubirdate 랑 purrr 연관성
lubridate와 purrr 패키지를 함께 적용 할 수도 있다.
purrr에는 map()함수가 있다. map() 함수는 반복적으로 연산 수행을 가능하게 해준다.
lubridate와 purrr의 map_*() 함수들이 결합하면 시간 연산을 더 빠르게 효율적으로 할 수 있다.
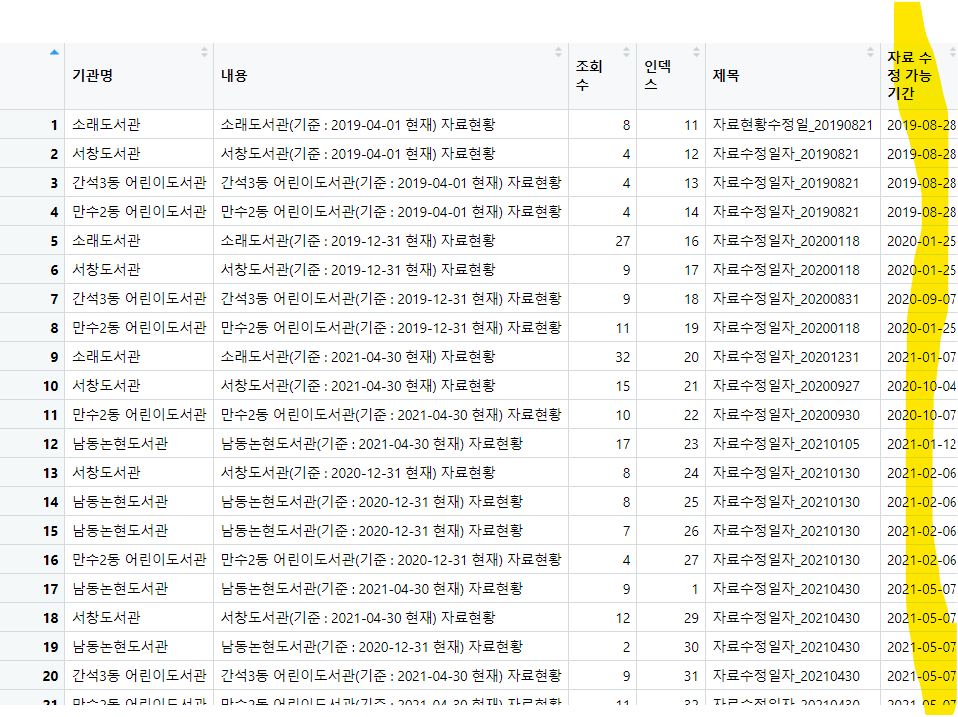
앞에서 사용했던 인천 도서관 데이터를 이용해보자자. 우리는 "자료 수정 가능 기간" 열을 새로 만들고 싶다고 하자.
날짜 열에 +7일이 수정 가능 날짜이다. map() 함수를 이용하여 효율적으로 시간 계산을 해보자.
<코드 구성>
1. 이전에 추출한 date 열을 가지고 자료 수정 가능 기간 열을 생성하자.
2. map(계산할 데이터, ~.x 함수 식 넣어주기)를 이용해서 작성해보자.
# 필요한 라이브러리 불러오기
library(dplyr)
library(stringr)
# Excel 파일 "인천 도서관.xlsx" 불러오기
library_data <- readxl::read_excel("인천 도서관.xlsx")
View(library_data)
# "제목" 열에서 stringr을 사용하여 날짜 정보 추출
date <- library_data$제목 %>% stringr::str_match(pattern = "\\d+")
date <- ymd(date)
# "자료 수정 가능 기간" 열 생성 및 특정 형식으로 날짜 표시
library_data <- library_data %>%
mutate("자료 수정 가능 기간" = map(date, ~ format(.x + days(7), "%Y-%m-%d")))
# 결과 확인
View(library_data)
처음에는 이와 같은 형식으로 코드를 작성했었다. 우리가 원하던것은 %Y %m %d 형식 이었는데 일수로 계산되어 버렸다.
library_data <- library_data %>%mutate("자료 수정 가능 기간" = map(date, ~ .x + days(7)))
그래서 format 함수를 씌어주기로 했다. format을 씌워서 %Y-%m-%d로 해달라고 하면 자연스럽게 년월일 형식으로 새로운 열이 추가된다.
library_data <- library_data %>%mutate("자료 수정 가능 기간" = map(date, ~ format(.x + days(7), "%Y-%m-%d")))<결과값>
lubridate랑 tidyr 연관성
◆ 대전, 세종시 월별 평균 발전량 구하기
<파일 불러오기>
먼저, 대전, 세종시 월별 평균 발전량을 구하기 위해 공공데이터포털에서 제공하고 있는 '한국전력거래소_대전, 세종시 발전량_20161231' CSV 파일을 사용했다.
한국전력거래소_대전, 세종시 발전량_20161231
전력시장에 참여하는 대전, 세종지역 발전기의 발전량 합계를 제공합니다.<br/>- 항목 : 지역, 날짜, 시간, 발전량<br/>- 단위 : Wh(0~55분 데이터 합산 시)<br/>- 기간 : 2016년
www.data.go.kr
<데이터 전처리하기>

해당 파일을 살펴보니, 위와 같이 거래일을 기준으로 시간 행과 분을 가리키는 행이 따로 존재하여, 이렇게 존재하는 데이터를 날짜와 시간을 모두 합쳐 "%Y-%m-%d %H:%M:%S"의 형식으로 나타내고 싶어서 tidyverse 패키지를 활용하여 데이터를 전처리해보았다.
1. 패키지 설치
if (!require("tidyverse")) install.packages("tidyverse")
if (!require("readr")) install.packages("readr")
if (!require("lubridate")) install.packages("lubridate")먼저, 해당 작업을 수행하기 위해 필요한 tidyverse 패키지와 readr 패키지, lubridate 패키지를 설치하였다.
2. 파일 불러오기
encoding <- readr::guess_encoding("한국전력거래소_대전, 세종시 발전량_20161231.csv")$encoding[1]
data <- read.csv("한국전력거래소_대전, 세종시 발전량_20161231.csv", fileEncoding = encoding)먼저, 해당 파일이 한국어로 이루어져 있기 때문에, 파일을 불러올 때 오류가 발생하는 것을 방지하기 위해 guess_encoding을 이용해 encoding을 추정한 후 이를 이용해 CSV 파일을 불러왔다.
3. 데이터 전처리하기
data_long <- data %>%
pivot_longer(cols = starts_with("X"),
names_to = "minute",
values_to = "value") %>%
mutate(minute = as.numeric(str_remove(minute, "X")),
datetime = as.POSIXct(paste(거래일, sprintf("%02d:%02d:00", 시간, minute)), format="%Y-%m-%d %H:%M:%S"))CSV 파일과 관련해 공부하다보니, R에서는 CSV 파일을 읽을 때 열 이름에 숫자만 있으면 유효한 변수 이름으로 인식하지 않기 때문에 "X"를 자동으로 추가한다는 것을 알게 되었다. 즉, 위에서 살펴본 '0', '5' 등과 같은 열 이름은 'X0', 'X5' 등으로 자동으로 변경된다. 따라서, 분을 나타내는 열들을 pivot_longer를 이용해 data를 'Long' 형태로 변경하고자 하였다.
* Long 형태
-> Long 형태는 각 변수를 하나의 열로 나타내는 방식을 의미한다.
<Wide 형태>
| ID | 변수 1 | 변수 2 | 변수 3 |
| 1 | A | X | 10 |
| 2 | B | Y | 15 |
| 3 | C | Z | 20 |
<Long 형태>
| ID | 변수 | 값 |
| 1 | 변수1 | A |
| 1 | 변수2 | X |
| 1 | 변수3 | 10 |
| 2 | 변수1 | B |
| 2 | 변수2 | Y |
| 2 | 변수3 | 15 |
| 3 | 변수1 | C |
| 3 | 변수2 | Z |
| 3 | 변수3 | 20 |
위의 표를 살펴보면, Wide 형태에서는 각 변수가 열로 표현되어 있는 반면에, Long 형태에서는 각 변수가 각각 하나의 열로 쌓여있다. Long 형태는 데이터를 분석하거나 시각화할 때 유연성을 제공한다. 이렇게 Long 형태로 변환하는 과정을 'Melting' 또는 'Reshaping'이라고 한다.
해당 과정을 거친 후, mutate 함수를 사용해 minute열과 datetime열을 생성해주었다.
minute열은 X를 제거하고 as.numeric 함수를 사용해 숫자로 변환한 결과를 minute열에 저장하였다.
datetime열은 먼저, sprintf 함수를 이용해 시간과 분 정보를 형식에 맞게 문자열로 변환해주었고, paste 함수를 이용해 날짜와 시간을 합쳐서 새로운 문자열을 생성하였으며, 마지막으로 as.POSIXct 함수를 이용해 POSIXct 형식으로 변환해주었다.
* sprintf()
-> sprintf 함수는 형식화된 문자열을 생성하는 데 사용되고, 특히 숫자나 문자열을 원하는 형식으로 표시하는데 유용하다.
sprintf(format, ...)format : 문자열의 형식을 지정하는 문자열. % 기호와 서식 지정자를 사용하여 특정 형식을 지정할 수 있다.
... : 형식에 대응하는 값을 나열한다.
( %d : 정수, %f : 실수, %s : 문자열)
위에서 사용한 %02d는 출력되는 정수의 최소 길이가 2자리이며, 만약 정수의 길이가 1자리라면 앞에 0을 붙여서 표시하도록 지정하는 서식이다.
4. 결과 출력하기
final_data <- data_long %>%
select(지역, datetime, value)
print(final_data)현재 필요한 열은 '지역', 'datetime', 'value'열이기 때문에 해당 열만 선택하여 최종 데이터를 만들어주었다.
전처리 과정을 거친 데이터는 다음과 같이 출력된다.

<대전, 세종시 월별 평균 발전량 구하기>
monthly_avg <- final_data %>%
mutate(month = format(datetime, "%Y-%m")) %>%
group_by(지역, month) %>%
summarise(avg_value = mean(value, na.rm = TRUE))
print(monthly_avg)먼저, datetime열에서 년도와 월 정보만 필요했기 때문에 mutate 함수를 이용해 month라는 새로운 열을 만들어주었다.
그 후, group_by 함수를 이용해 지역과 month열을 기준으로 데이터를 그룹화했고, summarise 함수를 이용해 그룹화된 데이터의 각 그룹에 대해 평균을 계산하여 avg_value로 나타내었다.
그 결과는 다음과 같다.

이렇게, tidyverse 패키지와 lubridate 패키지를 이용해 데이터들을 전처리하고, 문자열로 표현된 데이터들을 날짜 및 시간 객체로 변환해주는 과정을 통해 날짜와 시간과 관련된 목표 과제를 간편하게 수행할 수 있다.
가점항목 함수 예제 작성하고 넣기
saveRDS()
먼저 RDS란 R 전용 데이터 파일로 다른 파일들에 비해 R에서 읽고 쓰는 속도가 빠르고 용량이 작다는 장점이 있다.
일반적으로 R에서 분석 작업을 할때는 RDS 파일을 이용하고, R을 사용하지 않는 사람과 파일을 주고 받을 때는 CSV파일을 이용한다.
saveRDS()란 하나의 R객체를 R데이터 직렬화(RDS) 형식의 파일로 저장하는데 사용하는 함수이다.
위에서 언급했듯이 RDS 형식은 보다 효율적으로 이용할 수 있도록 하는 형식이다.
saveRDS()의 기본 구조를 알아보자.
saveRDS(object, file)object 는 저장하려는 R객체이고 데이터 프레임, 리스트 등이 될 수 있다.
file 은 객체를 저장할 파일의 이름이다.
예시는 다음과 같다.

이러한 데이터프레임을 my.rds라는 이름으로 저장해 보았다. 이제 이걸 출력해 보자.
그땐 readRDS가 필요하다.
readRDS()
- RDS파일을 읽을 때 사용하는 함수로 saveRDS()로 저장된 파일을 읽을 수 있다.
기본 구조는 다음과 같다.
readRDS(file)file : 위에서 저장한 파일 이름 즉 읽어올 파일의 이름을 적으면 된다.

이렇게 파일이 출력이 됨을 알 수 있다.
readRDS를 사용하지 않으면 파일이 읽어지지 않는다.

따라서 saveRDS()와 readRDS()는 함께 쓰기 좋은 함수라 할 수 있다.
difftime()
- 두 날짜나 시간 객체 사이의 차이를 계산하는 데 사용하는 함수로 주로 두 타임스탬프나 날짜 사이의 차이를 계산하는 데 사용된다.
다음은 difftime()함수의 기본 구조이다.
difftime(time1, time2, units="days")time1 과 time2 에는 두 날짜나 시간을 넣고 units에는 계산의 기준을 넣으면 된다. 지금은 '일'이 기준이지만
secs,mins,hours,weeks등이 될 수 도 있고 auto로 설정하면 적절한 것을 기준으로 계산을 해 줄 것이다. (years는 없다)
예시를 통해 함수에 대해 더 알아보자.

오늘로부터 태어난 날까지 며칠이 흘렀는지 계산해 보았다. units을 days로 잡으니 결과가 7605.09일이 나온 것이다. 다른 units을 기준으로 계산해보면 다음과 같다.

위에서 언급했듯이 years는 안되는 것을 확인할 수 있고 자동, 초, 주 를 기준으로 계산을 해보았다.
as.difftime()
- as.difftime()함수는 숫자 값이나 다른 시간 관련 객체를 difftime 객체로 변환하는 데 사용하는 함수이다. difftime 객체는 시간 기간을 나타내며 as.difftime()을 사용하면 변환할 때 시간의 단위를 지정할 수 있습니다.
as.difftime()함수의 기본 구조를 알아보자.
as.difftime(x, units = )x에는 difftime 객체로 변환하려는 숫자 또는 시간 객체가 들어간다.
unit에는 시간의 단위를 지정하는 걸로 difftime()에서 처럼 "auto", "secs","mins","hours","days","weeks"가들어갈 수 있다.
예시를 통해 더 알아보자.
as.difftime('09:30:00')-as.difftime('18:20:00')이렇게 as.difftime()함수를 통해 문자열을 difftime 시간 객체로 바꾸고 그 차이를 계산해 보았다.
to_days <- as.difftime(5, units = "days")
print(to_days)이렇게 일 단위 값을 difftime객체로 바꾸기도 가능하다.
as.difftime()이런식으로 사용할 수 있다.
as.numeric()
cumsum()
cummin()
cummax()
<lubridate과 함께 as.numeric, cumsum, cummax,cummin을 한꺼번에 이용한 예시>
as.numeric(),cumsum(),cummin(),cummax()를 한꺼번에 이용한 예제를 작성해보았다. 그 전에 각 함수에 대한 개념을 알아보자.
as.numeric()
as.numeric()은 데이터 타입을 numeric형으로 바꾸는 함수이다.
cumsum()
cumsum()은 벡터들의 누적합을 구해주는 함수이다. 원리는 아래와 같다.
vector <-c(1:10)
# 1,2,3,4,5,6,7,8,9,10
cumsum(vector)[1] 1 3 6 10 15 21 28 36 45 551, 1+2,1+2+3,1+2+3+4.. 로 합이 누적된다.
cummin()
cummin은 맨 처음 값을 출력하고 그 다음 값과 비교 후, 그 값이 더 작다면 해당 값을 출력하는 함수이다.
vector1 <-c(3:1,2:0,4:2)
vector1 #3,2,1,2,1,0,4,3,2
cummin(vector1)[1] 3 2 1 1 1 0 0 0 0
첫입력값 3은 그냥 그대로 출력하고 두번째엔 3보단 2가 더 작으므로 2를 출력해준다. 그 다음으로 2보단 1이 더 작으므로 1을 쭉 출력한다. 그러다가 0을 만나면 쭉 0으로 결과값이 처리된다.
cummax ()
cummax()는 맨 처음 값을 출력하고 그 다음값과 비교후 그 값이 더 크다면 해당 값을 출력한다. 원리는 다음과 같다.
vector2 <- c(3:1, 2:0, 4:2)
cummax(vector2)[1] 3 3 3 3 3 3 4 4 4첫입력값 3은 그냥 그대로 출력하고 쭉 가다가, 3보다 4가 크기 때문에 4를 최댓값으로 계속 출력해준다.
경상남도 진주시_폐차정보현황 데이터에는 차 최초 등록일과 말소일자가 나와있다. 작성할 스토리보드는 아래와 같다.
<코드 구성>
- POSIXct 형식으로 일단 쫙 바꿔준다.
- 이 중에 lubridate :: year() 함수를 사용해서 추출값이 2004년 이상이면 그 값들만 있는 행만 추출하기로 하자
- 말소일자- 최초 등록일자 =>( lubridate 데이터 끼리 연산이 가능하다고 했으니까 )를 해서 따로 쭉 뽑고, 이 과정에서 as.numeric cummsum을 이용하여 누적 합을 구해보자
- 이 중 말소일자-최초등록일자의 최댓값의 변화를 보기 위해 cummax를 사용하자 + 최소값의 변화를 보기 위해 cummin도 사용 할 거다.
library(readr)
library(dplyr)
library(lubridate)
#파일불러오기 => read_csv로 안 불러져서...하위버전으로 데이터 불러옴
data <- read.csv("경상남도 진주시_폐차정보현황_20230927.csv", fileEncoding = "euc-kr")
#1 POSIXct 객체로 쫙 바꿔주기
first_date <- data$최초등록일
finish_date <-data$말소일자
first_date<-ymd(first_date)
finish_date <-ymd(finish_date)
#2 이 중에 lubridate의 year() 함수를 사용해서 first_date의 year(년도)가 2004년 이상이면 그 값들만 있는 행만 추출
first_year_vector <- lubridate::year(first_date)
T_or_F_vector <- first_year_vector >= 2004
T_or_F_vector
filtered_data <- data[T_or_F_vector, ]
filtered_data
#3(말소일자- 최초 등록일자)를 해서 따로 쭉 뽑고 cummsum을 이용하여 누적 합을 구해보자
date_diff <- as.numeric(date(filtered_data$말소일자)- date(filtered_data$최초등록일))
date_diff
#cumsum 적용
cumsum(date_diff)
#1144212
#4 cummax랑 cummin 이용하기
#cummax 적용
cummax(date_diff)
#7036
#cummin 적용
cummin(date_diff)
#92lubridate를 이용하여 날짜 데이터 끼리는 시간 연산을 할 수 있다. 따라서, date() 끼리 묶어줘서 날짜끼리 연산을 해주었다. 그럼 아래와 같이 차이를 계산한 결과가 쭉 나타난다.

마지막으로 cumsum,cummax,cummin을 이용하여 누적데이터를 뽑았다.
<결과>
경상남도 폐차 기간의 총 누적합은 1144212일로 결정되었다.
또한, 최고 오래된 기간은 7036일이었다.
마지막으로 가장 최단으로 처리된 기간은 92일이었다. 92일만에 고속으로 폐차 처리 되었다.
file.create()
R 프로그래밍 언어에서 file.create() 함수는 새 파일을 생성하는 데 사용된다. 함수는 주어진 파일 경로에 새 파일을 만들고, 파일 생성이 성공적으로 이루어졌는지를 논리값 (TRUE 또는 FALSE)으로 반환한다.
file.create(filepaths)여기서 filepaths는 하나 이상의 문자열로 된 파일 경로를 나타낸다. 파일 경로는 절대 경로나 상대 경로일 수 있다.
# 단일 파일 생성
result <- file.create("example.txt")
print(result) # 파일 생성이 성공했는지 확인
# 여러 파일을 한 번에 생성
result <- file.create(c("file1.txt", "file2.txt", "file3.txt"))
print(result) # 각 파일 생성에 대한 결과
이미 존재하는 파일 이름으로 file.create()를 호출하면 기존 파일은 변하지 않고, 함수는 FALSE를 반환한다.
파일 생성에 필요한 쓰기 권한이 없는 디렉토리에 파일을 생성하려고 하면, 함수는 FALSE를 반환합니다.file.create()는 파일을 생성하기만 하며, 내용을 추가하거나 수정하는 기능은 없다.
파일 내용을 추가하거나 수정하려면 write 계열의 함수 (예: write.table, writeLines)를 사용해야 한다.
> library(lubridate)
>
> # 현재 시간을 기반으로 파일 이름 생성
> current_time <- now()
> file_name <- paste(format(current_time, "%Y-%m-%d_%H-%M-%S"), "report.csv", sep = "_")
>
> # 파일 경로 생성
> file_path <- file.path("GitHub/now/", file_name)
>
> # 파일 생성
> file.create(file_path)
[1] TRUE
file.copy()
file.copy() 함수는 R 프로그래밍 언어에서 파일을 복사하는 데 사용된다. 이 함수는 하나 이상의 파일을 지정된 목적지로 복사하고, 각 파일 복사가 성공적으로 이루어졌는지를 나타내는 논리값 (TRUE 또는 FALSE)을 반환한다.
file.copy(from, to, overwrite = FALSE, recursive = FALSE)
from: 복사할 파일 또는 디렉토리의 경로.
to: 파일이나 디렉토리가 복사될 목적지 경로.
overwrite: 이미 목적지에 파일이 존재할 경우 덮어쓸지 여부를 결정하는 논리값. 기본값은 FALSE이다.
recursive: 디렉토리를 복사할 경우, 하위 디렉토리와 파일을 모두 복사할지 여부를 결정하는 논리값. 기본값은 FALSE이다.
# 단일 파일 복사
result <- file.copy("source.txt", "destination.txt")
print(result) # 파일 복사가 성공했는지 확인
# 여러 파일을 한 번에 다른 디렉토리로 복사
files_to_copy <- c("file1.txt", "file2.txt", "file3.txt")
result <- file.copy(files_to_copy, "destination_directory/")
print(result) # 각 파일 복사에 대한 결과
# 파일을 덮어쓰기
result <- file.copy("source.txt", "existing_file.txt", overwrite = TRUE)
print(result) # 파일 덮어쓰기가 성공했는지 확인
복사하려는 파일이 존재하지 않거나, 목적지 경로가 잘못되었을 경우 FALSE를 반환한다.
overwrite = FALSE로 설정된 경우, 목적지에 동일한 이름의 파일이 이미 존재하면 복사 작업이 실패하고 FALSE를 반환한다.
디렉토리를 복사하려면 recursive = TRUE를 설정해야 한다.
file.path()
file.path() 함수는 R 프로그래밍 언어에서 파일 경로를 구성하는 데 사용된다. 이 함수는 플랫폼에 독립적인 방식으로 파일 경로를 만들어준다. 즉, 윈도우, 맥, 리눅스 등 다양한 운영 체제에서 동일하게 작동하며, 각 운영 체제에 맞는 경로 구분자를 사용한다.
file.path(..., fsep = .Platform$file.sep)
...: 하나 이상의 문자열 인자들. 이들은 연결되어 파일 경로를 형성한다.
fsep: 파일 구분자. 기본적으로 시스템의 파일 구분자를 사용합니다 (예: 윈도우에서는 \, 유닉스 계열에서는 /).
# 기본적인 파일 경로 생성
path <- file.path("my_directory", "subdirectory", "file.txt")
print(path) # "my_directory/subdirectory/file.txt"
# 더 복잡한 파일 경로 생성
path <- file.path("C:", "Users", "username", "Documents", "R", "scripts", "script.R")
print(path) # "C:/Users/username/Documents/R/scripts/script.R"
file.path()는 단순히 문자열을 연결하여 경로를 생성한다. 이 함수는 생성된 경로가 실제로 존재하는지, 또는 유효한지 확인하지 않는다.
파일 시스템의 규칙에 따라 경로를 올바르게 구성하도록 주의해야 한다. 예를 들어, 윈도우 시스템에서는 드라이브 문자 (예: C:)로 시작하는 경로를 만들 수 있다.
경로를 생성한 후에는 file.exists() 함수를 사용하여 해당 경로에 파일이나 디렉토리가 실제로 존재하는지 확인할 수 있다.
file.rename()
file.rename() 함수는 파일 또는 디렉토리의 이름을 변경하는 데 사용되는 함수이다. 기존 파일 또는 디렉토리의 이름을 새로운 이름으로 변경할 때 사용된다.
<file.rename()의 기본 형식>
file.rename(from, to)from : 변경하려는 파일 또는 디렉토리의 현재 이름을 나타내는 문자열 또는 문자열 벡터.
to : 새로운 이름을 나타내는 문자열 벡터.
* 만약, 여러 파일의 이름을 동시에 변경할 경우에는 to에 지정되는 문자열 벡터와 from에 지정되는 문자열 벡터의 길이가 같아야 한다.
<file.rename()의 사용 예시>
file.rename("old_filename.txt", "new_filename.txt")
만약, 여러 파일의 이름을 동시에 변경하고 싶다면, 아래 코드와 같이 'from'과 'to'에 각 파일의 현재 이름과 새로운 이름을 나타내는 문자열 벡터를 전달하면 된다.
files_to_rename <- c("old_file1.txt", "old_file2.txt")
new_names <- c("new_file1.txt", "new_file2.txt")
file.rename(files_to_rename, new_names)* 파일 이름을 변경하려면 해당 파일이나 디렉토리가 존재해야 하고, 파일 이름 변경이 실패하면 오류가 발생하기 때문에, 변경 전에 파일의 존재 여부를 확인하는 것이 좋다.
file.size()
file.size() 함수는 파일의 크기를 바이트 단위로 변환하는 함수로, 특정 파일의 크기를 손쉽게 확인할 수 있다.
<file.size()의 기본 형식 및 사용 예시>
file_path <- "your_file.txt"
size_in_bytes <- file.size(file_path)위와 같이 file_path 변수에는 크기를 확인하고자 하는 파일의 경로가 들어가야 하고, file.size() 함수를 사용하여 해당 파일의 크기를 바이트 단위로 가져올 수 있다.
* file.size() 함수는 파일이 존재하지 않는 경우에 0을 반환한다. 따라서, 아래 코드와 같이 파일의 크기를 얻기 전에 존재 여부를 확인하는 것이 좋다.
file_path <- "your_file.txt"
if (file.exists(file_path)) {
size_in_bytes <- file.size(file_path)
print(paste("File size:", size_in_bytes, "bytes"))
} else {
print("File does not exist.")
}
만약, 파일의 크기를 사람이 읽기 쉬운 형식인 킬로바이트(KB)나 메가바이트(MB) 등으로 표시하고 싶다면, 포맷을 변경해주는 방식으로, 파일의 크기를 출력할 수 있다.
아래 코드는 바이트를 킬로바이트(KB)로 변환하여 크기를 출력하는 코드이다.
file_path <- "your_file.txt"
size_in_bytes <- file.size(file_path)
size_in_kb <- size_in_bytes / 1024
print(paste("File size:", size_in_kb, "KB"))위와 같은 방식을 이용해 파일의 크기를 메가바이트(MB) 등으로 출력하는 것도 모두 가능하다.
위의 코드들을 사용해 '한국전력거래소_대전, 세종시 발전량_20161231.csv' 파일의 크기를 알아보겠다.
file_path <- "한국전력거래소_대전, 세종시 발전량_20161231.csv"
if (file.exists(file_path)) {
size_in_bytes <- file.size(file_path)
print(paste("File size:", size_in_bytes, "bytes"))
} else {
print("File does not exist.")
}
[1] "File size: 2234488 bytes"위와 같이 해당 csv 파일의 크기는 2234488 byte라는 것을 알 수 있다.
file_path <- "한국전력거래소_대전, 세종시 발전량_20161231.csv"
size_in_bytes <- file.size(file_path)
size_in_kb <- size_in_bytes / 1024
print(paste("File size:", size_in_kb, "KB"))
[1] "File size: 2182.1171875 KB"이를 킬로바이트로 변환하여 나타내면 좀 더 알아보기 쉽게 2182 KB라고 변환되어 출력된다.
file.choose()
file.choose() 함수는 대화형으로 파일을 선택할 수 있는 파일 선택 대화 상자를 열어주는 함수이다. R GUI 환경에서 유용하며, 사용자에게 파일을 선택하도록 할 때 사용된다.
* R GUI 환경
-> R 프로그래밍 언어를 그래픽 사용자 인터페이스(Graphical User Interface, GUI)를 통해 제어하고 상호 작용할 수 있는 환경
-> 주로 통합 개발 환경(IDE)인 Rstudio와 함께 사용되며, 사용자가 스크립트를 작성하고 실행하며, 데이터를 시각화하고 분석하는 데 도움을 주는 다양한 도구를 제공한다.
<file.choose()의 작동 방식>
selected_file <- file.choose()
print(selected_file)
1. 함수를 호출하면 사용자에게 파일 선택 대화 상자가 나타남.

2. 사용자가 파일을 선택하면 해당 파일의 경로가 R 스크립트에 반환됨.
selected_file <- file.choose()
print(selected_file)
[1] "/cloud/project/소비자물가지수_2020100__20231031170343.csv"
* file.choose() 함수는 대화형 환경에서 사용할 때 유용하고, 스크립트를 자동으로 실행하지 않는 환경에서는 적합하지 않을 수 있다.
file.remove()
file.remove() 함수는 R에서 파일이나 디렉토리를 삭제하는 함수이다. 주어진 파일 또는 디렉토리를 지정된 경로에서 삭제한다. 이 접근 방식에서는 사용자가기본 함수인 file.remove() 함수를 호출하기만 하면 되고, 이 함수에서 사용자는 경로/ 삭제할 파일의 이름을 이 함수의 매개변수로 지정하고, 이를 통해 사용자는 제공된 경로/이름에 따라 파일을 삭제할 수 있다.
<예시>
file.remove('gfg_data1.csv')
file.remove('gfg_data1.csv')
file.remove('gfg_data2.csv')
#결과
[1] TRUE
[2] TRUE
여러개 파일 제거
# 여러 파일 제거
제거할_파일들 <- c("파일1.txt", "파일2.csv", "파일3.txt")
file.remove(제거할_파일들)
전체 경로를 사용하여 파일 제거
# 전체 경로를 사용하여 파일 제거
전체_경로의_파일들 <- c("경로/에서/파일1.txt", "경로/에서/파일2.csv", "경로/에서/파일3.txt")
file.remove(전체_경로의_파일들)
디렉토리 내의 파일 제거
# 디렉토리 내의 모든 파일 제거
디렉토리_경로 <- "경로/에서/디렉토리"
file.remove(list.files(디렉토리_경로, full.names = TRUE))
재귀적으로 파일 제거
# 디렉토리 내에서 재귀적으로 파일 제거
디렉토리_경로 <- "경로/에서/디렉토리"
file.remove(list.files(디렉토리_경로, full.names = TRUE, recursive = TRUE))
파일 제거 확인
# 파일을 제거하고 성공적으로 제거되었는지 확인
파일_제거_여부 <- file.remove("파일.txt")
if (all(파일_제거_여부)) {
print("파일이 성공적으로 제거되었습니다.")
} else {
print("일부 파일이 제거되지 않았습니다.")
}
예시)
>> 현재는 파일이 3개 있는 것을 볼 수 있다.

<파일 삭제 실행 코드>
#this_file을 삭제하기 위한 파일 정의
<- " C:/Users/bob/Documents/my_data_files/soccer_data.csv "
#파일이 있으면 삭제합니다.
if ( file.exists (this_file)) {
파일. (this_file) 제거
cat(" 파일이 삭제되었습니다 ")
} 또 다른 {
cat(" 파일을 찾을 수 없습니다 ")
}
파일이 삭제되었습니다.
<결과>

>> 파일이 2개로 파일 1개가 성공적으로 삭제된 것을 볼 수 있다.
+ unlink()를 사용해서 file을 삭제해보자
파일을 삭제하는 이 접근 방식에서 사용자는 삭제될 파일의 경로/이름을 이 함수의 매개 변수로 사용하여 unlink() 함수를 호출하면 된다. 사용자는 제공된 경로/이름에 따라 파일을 삭제할 수 있다.
Unlink() 함수는 x로 지정된 파일이나 디렉터리를 삭제한다.
Syntax:
unlink(x, recursive = FALSE, force = FALSE)
Parameters:
- x: 삭제할 파일 또는 디렉터리의 이름이 포함된 문자형 벡터.
- recursive: 논리적. 디렉토리를 재귀적으로 삭제해야 하나
- force: 논리적. 파일이나 디렉터리를 제거할 수 있도록 권한을 변경해야 할까(가능한 경우)
<예시>
unlink('gfg_data3.csv', recursive = FALSE, force = FALSE)
list.dirs()
"dirs"라는 용어는 "directories(디렉토리)"의 줄임말이다.
R의 list.dirs() 함수에서 "dirs"는 파일 시스템 내의 디렉토리나 폴더를 가리킨다.
이 함수는 이러한 디렉토리의 이름을 나열하거나 가져오는 데 사용된다.
이 함수를 사용하면 주어진 경로 내에 있는 하위 디렉토리에 관한 정보를 얻을 수 있다.
그래서 list.dirs()라고 말할 때, 이 함수를 사용하여 특정 디렉토리 내의 하위 디렉토리를 나열하거나 검색하는 것을 의미한다. 이 함수는 폴더 구조와 특정 위치에 존재하는 디렉토리에 대한 정보를 얻을 수 있는 유용한 기능이다.
사용법:
list.dirs(path = ".", full.names = FALSE, recursive = TRUE)- path: 하위 디렉토리를 나열하려는 디렉토리의 경로이다. 기본값은 현재 작업 디렉토리 (".")이다.
- full.names: 논리형. TRUE로 설정하면 결과에 각 디렉토리의 전체 경로가 포함된다. FALSE (기본값)로 설정하면 디렉토리의 이름만 반환된다.
- recursive: 논리형. TRUE로 설정하면 함수는 하위 디렉토리를 재귀적으로 검색한다. FALSE로 설정하면 즉시 아래의 하위 디렉토리만 나열한다.
- 이 함수는 지정된 경로 내의 디렉토리 이름(또는 경로)을 포함하는 문자열 벡터를 반환한다.
- 기본적으로 숨겨진 디렉토리와 숨겨지지 않은 디렉토리 모두를 포함합니다. full.names 인수를 사용하여 이 동작을 제어할 수 있다.
- recursive가 TRUE로 설정되면 함수는 하위 디렉토리를 재귀 검색하여 하위 디렉토리의 하위 디렉토리도 포함한다.
예시)

# specifying the path
main_dir <- "/Users/mallikagupta/Desktop/gfg"
print ("list of directories including the main directory")
dir_list <- list.dirs(main_dir,recursive = TRUE)
print (dir_list)
print ("list of directories excluding the main directory")
dir_list <- list.dirs(main_dir,recursive = FALSE)
print (dir_list)
<결과>
# 메인 디렉터리를 포함한 디렉터리 목록
[1] “/Users/mallikagupta/Desktop/gfg” “/Users/mallikagupta/Desktop/gfg/인터뷰”
[3] “/Users/mallikagupta/Desktop/gfg/Placements” “/Users/mallikagupta/Desktop/gfg/WFH”
# 메인 디렉터리를 제외한 디렉터리 목록
[1] “/Users/mallikagupta/Desktop/gfg/Interviews” “/Users/mallikagupta/Desktop/gfg/Placements”
[3] “/Users/mallikagupta/Desktop/gfg/WFH”
기본 디렉터리를 제외하는 또 다른 방법은 하위 디렉터리만 반환하는 list.dirs() 에 추가된 [-1] 인덱스를 지정하는 것이다.
main_dir <- "/Users/mallikagupta/Desktop/gfg"
print ("list of directories")
dir_list <- list.dirs(main_dir)[- 1]
print (dir_list)
<결과>
# 디렉토리 목록
[1] “/Users/mallikagupta/Desktop/gfg/Interviews” “/Users/mallikagupta/Desktop/gfg/Placements”
[3] “/Users/mallikagupta/Desktop/gfg/WFH”
폴더 이름 얻기
기본 디렉터리 내의 폴더 또는 디렉터리 이름만 검색할 수 있다. 이 경우 메소드 호출에서 full.names = FALSE 매개변수를 설정했다. 이름은 알파벳순으로 정렬되어 있다.
<예시>
main_dir <- "/Users/mallikagupta/Desktop/gfg"
print ("list of directory names")
dir_list <- list.dirs(main_dir,full.names = FALSE,
recursive = FALSE)
print (dir_list)[1] “Interviews” “Placements” “WFH”
list.files()
list.files() 함수는 R에서 지정된 디렉토리 내의 파일 이름 목록을 얻기 위해 사용된다. list.files() 함수를 사용하여 특정 폴더의 모든 파일을 나열할 수 있다. 이 함수는 디렉토리 내의 파일에 대한 정보를 가져올 수 있으며, 파일 조작, 데이터 가져오기 또는 디렉토리 내용 탐색과 같은 작업에 유용하다. 또한 여러 가지 파일이 있고 그 파일들을 한꺼번에 분석해야 할 경우에도 유용하게 쓰인다.
사용법:
list.files(path = ".", pattern = NULL, all.files = FALSE, full.names = FALSE, recursive = FALSE)- path: 파일을 나열하려는 디렉토리의 경로이다. 기본값은 현재 작업 디렉토리 (".")입니다.
- pattern: 정규 표현식이다. 이 패턴과 일치하는 파일 이름만 반환된다. 기본값은 NULL로, 모든 파일이 나열된다.
- all.files: 논리형이다. TRUE로 설정하면 숨겨진 파일(점으로 시작하는 파일)도 목록에 포함된다. 기본값은 FALSE이다.
- full.names: 논리형이다. TRUE로 설정하면 결과에 각 파일의 전체 경로가 포함된다. FALSE (기본값)로 설정하면 파일의 이름만 반환된다.
- recursive: 논리형이다. TRUE로 설정하면 함수는 하위 디렉토리에서 파일을 재귀적으로 검색할 수 있다. FALSE (기본값)로 설정하면 지정된 디렉토리에서만 파일을 나열한다.
예시)
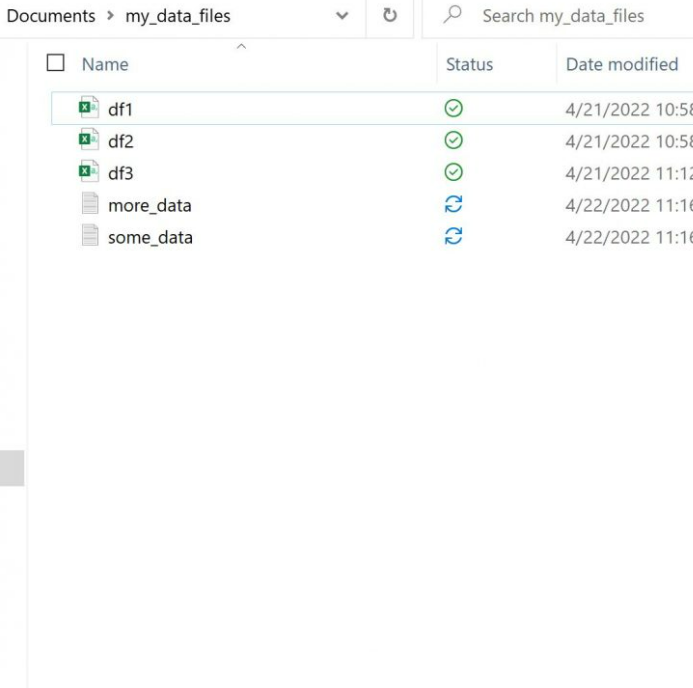
다음 예에서는 세 개의 CSV 파일과 두 개의 TXT 파일이 포함된 my_data_files 라는 폴더를 사용하
여 다양한 방법으로 파일들을 추출해보겠다.
모든 파일 나열
다음 구문을 사용하여 이 폴더의 모든 파일을 나열할 수 있다.
#my_data_files 폴더 목록의 모든 파일을 표시하기
list.files('C:/Users/bob/Documents/my_data_files')
[1] "df1.csv" "df2.csv" "df3.csv" "more_data.txt" "some_data.txt"
-> 이 폴더에 있는 5개 파일의 이름을 모두 볼 수 있다.
#my_data_files 총 파일 수 나열
length(list.files('C:/Users/bob/Documents/my_data_files'))-> 폴더에 파일이 몇 개 있는지 알고 싶다면 length() 함수를 사용할 수도 있다.
디렉터리의 처음 N개 파일 나열
인덱스를 사용하여 이 폴더에서 관심있는 처음 세 개의 파일만 나열할 수 있다.
#폴더 목록의 처음 세 개 파일 나열하기
list.files('C:/Users/bob/Documents/my_data_files')[1:3]
특정 확장자를 가진 디렉터리의 모든 파일 나열
# my_data_files 폴더 목록에 CSV 확장자를 가진 모든 파일을 표시하기
list.files('C:/Users/bob/Documents/my_data_files', pattern='csv')
[1] "df1.csv" "df2.csv" "df3.csv"-> 또한 패턴 인수를 사용하여 특정 확장자를 가진 파일만 나열할 수도 있다.
문자열을 포함하는 디렉터리의 모든 파일 나열
# 파일 이름 목록에 'data'가 포함된 모든 파일을 표시하기
list.files('C:/Users/bob/Documents/my_data_files', pattern='data')
[1] "more_data.txt" "some_data.txt"-> 패턴 인수를 사용하여 특정 문자열을 포함하는 파일만 나열할 수도 있다.